Have you ever wondered how a website knows that you’ve input a valid email address or phone number when signing up for an account? Maybe you’d like to parse through a website or text file, searching for and storing all dates of the form YYYY-MM-DD? Where there’s a problem that relates to the formatting of strings, regular rexpressions, often abbreviated as ‘regex’, is a tool that’s not far behind. Regex is a powerful set of expressions that describe patterns of characters, allowing one to search for these patterns in a given string.
This tutorial will walk through the utilization of regex to solve a problem that my group faced as we worked to web scrape and format the data that we’re working with. Namely, how can we re-add spaces to city names that were concatenated during the data cleaning process? (For example, how can we convert the string ‘SaintPaul’ into ‘Saint Paul’?) As we were dealing with thousands of entries, parsing through the data manually was impractical, and thus we turned to other methods to solve this problem. This is where regular expressions came in.
We will be utilizing the online resource regexr to learn the basics of regular expressions, and then use the knowledge gained from that website to create a short and simple Python script that solves the presented problem.
Finding Our Footing
Upon opening the website for the first time, you’ll be met with an overwhelming amount of panels, documentation, and tools. Let’s focus on the top right corner of the page for a moment:

There are two main elements here: An editable regular expression of the form /([A-Z])\w+/g, and a sample text with a collection of words highlighted. These highlighted words are the ones that match the formatting of the aforementioned regular expression. So what does /([A-Z])\w+/g actually mean? Let’s break it down:
/ indicates that beginning of a regular expression pattern.([A-Z]) matches whenever a character in the string is a capital letter in the English alphabet from A-Z.\w matches whenever a character is considered a “word character” (i.e, it is a letter of the alphabet, a number, or an underscore).+ tells the expression to continue matching all of the characters that fit the aforementioned pattern (in this case, \w) until it finds one that doesn’t./ indicates that the regular expression pattern is completed.g tells the console to perform a global search on the text file. (That is, highlight every possible string in the text that matches the aforementioned pattern, not just the first one.)
Putting this all together, this is a regular expression that returns all words in a text that start with a capital letter!
Now that we’ve defined every part of the regular expression, play around a bit with the regular expression by editing different components. What happens to the highlighted words if we change the character range to [a-z], or [A-C]? What happens if we delete the +, what about the \w? We’ll use this knowledge of regex formatting to help us construct our own regular expression to find where we should input spaces.
Writing Our Regular Expression
Equipped with the knowledge of some basic regular expression syntax, we’re now ready to tackle the question at hand: how can we use regular expressions to input spaces into a string? We knew from our manipulation of the dataset that all of the cities that we wanted to look for were of the form “NewYork”, “SanFrancisco”, “LosAngeles”, etc. One can observe that in every one of these strings, the place that we want to add a string lies right before a capital letter, but not just any capital letter. Specifically, we only want the search to yield capital letters that are preceded by a word character. (Otherwise we would add unnecessary spaces at the beginning of each string.) From our previous research, we know that we can match a word character with \w, and capital letters with [A-Z]. Putting those two things together, we conclude that the regular expression /(\w)([A-Z])/g will return the characters directly before and directly after everywhere we wish to add a space. For example, searching the string “NewYork” will yield “wY”.
Writing Our Test Cases
Inputting this newly constructed regular expression into the “expression” bar at the top, we notice that a new collection of characters have been highlighted, and the results look promising!
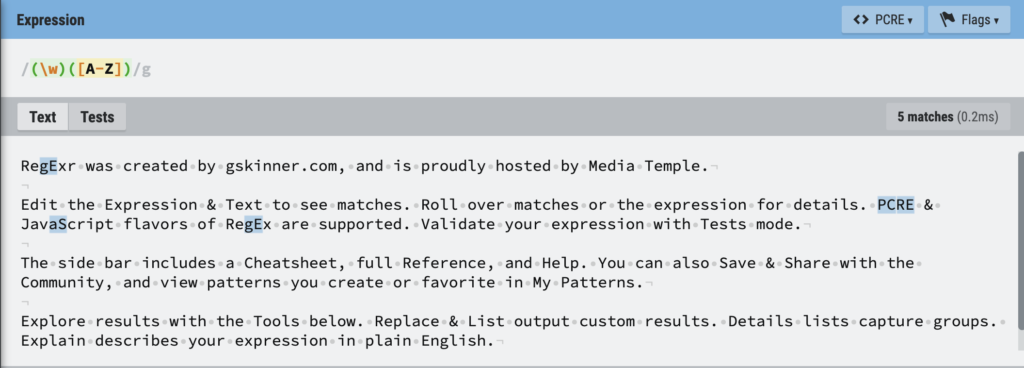
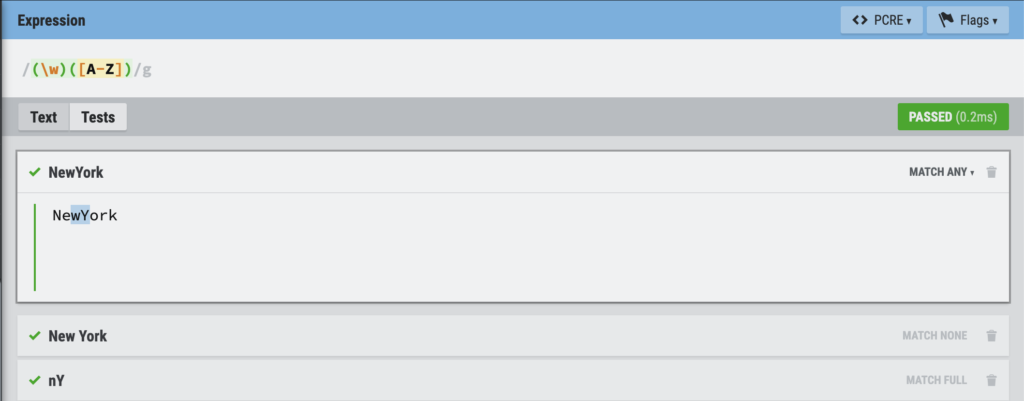
If we so desired, we could also utilize RegExr’s built in unit test function to further test our expression. By clicking on the “Tests” tab next to “Text,” one is brought to a user interface that allows for three different kinds of tests:
The first test, “MATCH ANY,” will pass if there exists a correct pattern of characters in the test string. (E.g, NewYork)
The second test, “MATCH NONE,” will only pass if nothing in the test string is of the correct format. (E.g, New York)
The third test, “MATCH FULL,” will pass only if the entire test string is of the correct format. (E.g, nY)
As the regular expressions that you develop become more and more complex, unit testing becomes all the more invaluable. Starting with a few simple, bite sized strings that you know how you’d like them to interact with your finalized regular expression is a great way of making sure the expressions are actually doing what you want them too, and can also speed up the development process!
Thinking Pythonically
Now that we’ve created a regular expression that locates everywhere that we want to add a space, our next step is to actually add that space! One way to do this is to utilize Python’s regular expression library re, which has a function that allows one to replace every component of the string that fits a given regular expression pattern with something else. In this case, we’re going to replace it with the same thing, except with a space in between the two characters. A step by step example of this process is as follows:
The string “NewYork” is passed in
The regular expression search yields the substring “wY”
The regular expression substitution replaces this sequence with “w Y”
Thus, the full string becomes “New York”
Python’s substitution follows this format:
re.sub(pattern, repl, string)
“pattern” is simply the regular expression that we’ve already developed (i.e, /(\w)([A-Z])/), and “string” is the string on which we want to apply the search. In the example above, that was “NewYork”. Finally, “repl” is the regular expression utilized to replace the elements of the string that match the search pattern. The input for this is going to require a little bit more knowledge of regular expressions. I propose that the formatting for this expression should be as follows: \1 \2. Let’s take a look:
\1 is the first character unit of the regular expression, in this case, the \w, or the “w” of “wY” to continue our example.\2 refers to the second character unit of the regular expression. (i.e, ([A-Z])) More concretely, this would therefore refer to the “Y” of “wY” in our example.
Therefore, the space between them in the\1 \2 expression is how the program knows to add a space in between these characters.
Putting Everything Together
Finally, we can combine everything that we’ve learned together to construct a Python function that takes in a string, and returns a correctly spaced string:
import re
def add_spaces(string):
return re.sub(r"(\w)([A-Z])", r"\1 \2", string)We can then use this function in tandem with a library that allows for the manipulation of CSV files, such as Python’s CSV library, or the Python data science library pandas’ dataframe data structure to edit the desired elements of a CSV.
And with that, you’ve successfully created and utilized your first regular expression!
Here are a few more resources to check out if you’d like to explore regular expressions further:
Official Python documentation on the re library
regexlib has a fantastic compilation of tools, books, and othersuch resources for those interested in learning more about regex
Hello Dominic! I like how your tutorial is logical and easy to follow. You explained the thought process behind the regular expression very well.
Dominic, this post is super helpful and very clear! I took a stab at learning regex expressions earlier in the term, but was completely baffled for the most part. Your explanation really helped me understand them better. Particularly, the “test” tool on the RegExpr website seems very useful. I would imagine that RegEx could have interesting applications not only in data cleaning, but also in text analysis (like Voyant Tools). I wonder if literary critics could use them to pick out certain patterns in texts, like syntactic constructions, for example. Thanks for this!
Hi Dominic! This was a very helpful tutorial – I’ve been scratching my head trying to figure out what these regex expressions mean and this was super enlightening.